HAL Id: tel-00308620
https://tel.archives-ouvertes.fr/tel-00308620
Submitted on 31 Jul 2008
HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci- entific research documents, whether they are pub- lished or not. The documents may come from
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de
Sécurisation du Contrôle d’Accès dans les Bases de Données
Luc Bouganim
To cite this version:
Luc Bouganim. Sécurisation du Contrôle d’Accès dans les Bases de Données. Informatique [cs].
Université de Versailles-Saint Quentin en Yvelines, 2006. �tel-00308620�
Sécurisation du contrôle d’accès dans les bases de données
Luc BOUGANIM
Rapport scientifique pour l’obtention de l’
HABILITATION A DIRIGER LES RECHERCHES EN INFORMATIQUE
Université de Versailles Saint-Quentin-en-Yvelines 27 janvier 2006
Rapporteurs :
Frédéric CUPPENS
(Professeur, ENST Bretagne, Rennes)Pierre PARADINAS
(Professeur, CNAM, Paris)Dennis SHASHA
(Professeur, New York University, New York, USA)Membres :
Claude KIRCHNER
(Directeur de recherche, INRIA & LORIA, Nancy)Philippe PUCHERAL
(Professeur, UVSQ, Versailles – INRIA, Rocquencourt)Patrick VALDURIEZ
(Directeur de recherche, INRIA, Rennes)Remerciements
Table des matières
Préambule 3
Travaux initiaux 7
1. Contexte 7
2. Exécution parallèle de requêtes : l’équilibrage de charge (thèse, 1993–1996) 8 3. Modèles d'exécution adaptatifs (INRIA, 1997–1999) 9 4. Prise en compte de fonctions coûteuses (INRIA, 1999–2002) 11
Chapitre 1 : Introduction 15
Chapitre 2 : Attaques, attaquants et instruments 19
1. Attaques et attaquants 19
2. Instruments : Techniques cryptographiques et composants matériels sécurisés 21 Chapitre 3: PicoDBMS, une approche basée sur un composant matériel sécurisé 25
1. Etat de l’art 25
2. Approche 26
3. Contribution 27
4. Conclusion 30
5. Résultats 31
Chapitre 4 : C-SDA, une approche hybride utilisant un SGBD relationnel 33
1. Etat de l’art 33
2. Approche 35
3. Contribution 35
4. Conclusion 39
5. Résultats 39
Chapitre 5 : Approches hybrides basées sur un stockage externe non sécurisé 41
1. Architecture générique 41
2. Etat de l’art 42
3. Approche 43
4. Conclusion 45
Chapitre 6 : Une approche hybride pour des documents XML 47 1. Sémantique du contrôle d’accès sur des documents XML 47
2. Etat de l’art 48
3. Approche 50
4. Contribution 50
5. Conclusion 53
6. Résultats 54
Chapitre 7: Conclusion et travaux futurs 55
1. Evolution matérielle des composants sécurisés 56
2. Sémantique du contrôle 58
3. Architectures 60
Bibliographie 63 Annexe A : PicoDBMS: Scaling down Database Techniques for the Smartcard 73 Annexe B : Chip-Secured Data Access: Confidential Data on Untrusted Servers 89 Annexe C : Client-Based Access Control Management for XML documents 103
Préambule
Ce préambule a pour objectif de situer mes activités de recherche dans le temps. En effet, la suite de ce document structure l'ensemble des travaux de recherche que j'ai mené en fonction de leur problématique scientifique et non en fonction de leur chronologie ou des projets dans lesquels ils ont été intégrés.
J'ai obtenu ma thèse de doctorat [Bou96] de l'Université de Versailles en Décembre 1996, sous la direction de Patrick Valduriez, directeur de recherche et responsable du projet RODIN à l’INRIA. Cette thèse a débuté dans l’équipe ‘bases de données avancées’ de Bull SA (Les Clayes sous Bois) et s’est poursuivie1 dans l’équipe RODIN. Le thème de ma thèse était l’équilibrage de charge lors de l’exécution parallèle de requêtes relationnelles. En effet, un obstacle majeur à l'obtention de bonnes performances réside dans l'équilibrage de la charge entre les différents processeurs exécutant une requête; le temps de réponse étant égal à celui du processeur le plus chargé. J’ai abordé ce problème en considérant successivement trois types d’architectures parallèles : (i) à mémoire partagée; (ii) hiérarchique; et (iii) à mémoire non uniforme. Ces travaux ont été fait dans le cadre du projet ESPRIT-II nommé EDS (European Declarative System) dont l’objectif était de réaliser une machine parallèle ainsi que le serveur base de données associé. Les résultats de mes travaux ont été implantés dans le prototype DBS3 (Database System for Shared Store).
J’obtiens, en 1997, un poste de Maître de Conférences à l’Université de Versailles - Saint Quentin et effectue mon enseignement à l’IUT de Mantes la Jolie. Je poursuis alors mes activités de recherche en collaboration avec l’équipe RODIN, toujours sur des problèmes liés à l’exécution de requêtes complexes, mais en me concentrant sur la ressource mémoire puis à la disponibilité des données lors de requêtes d’intégration dans le cadre du projet DISCO (système d’intégration de données dont sera issue la start-up Kelkoo). Ces travaux se font dans le cadre de l’encadrement de la thèse d’Olga Kapitskaia, ‘Traitement de requêtes dans les systèmes d'intégration des sources de données distribuées’ [Kap99].
1 Le changement d’équipe a fait suite à l’arrêt de l’activité de recherche en bases de données aux Clayes sous Bois.
En 1999, je suis collaborateur extérieur à l’INRIA, mais dans l’équipe CARAVEL2 et travaille alors au support de fonctions coûteuses dans l’exécution de requêtes distribuées dans le cadre du système de publication et d’intégration LeSelect. J’initie ces travaux avec Fabio Porto, étudiant brésilien en thèse ‘sandwich’, que j’encadre pendant l’année qu’il passe en France [Por01]. Je poursuis ces travaux en 2000, avec Ioana Manolescu, doctorante avec qui je travaille pendant environ 1 an [Man01]. Une partie de ces travaux sont actuellement implantés dans la version industrielle de LeSelect, distribuée par la start-up Medience (issue de l’équipe CARAVEL).
Dans la même période (i.e., à partir de 1999), nous entamons, au PRiSM, avec Philippe Pucheral, des recherches sur l’ubiquité et la confidentialité des données, motivées par une prise de conscience de l’importance croissante des problèmes liés à la confidentialité dans le domaine des bases de données. Je participe à la création d’une nouvelle équipe sur ces thèmes au PRiSM dont Philippe Pucheral sera le directeur.
En 2000, nous proposons PicoDBMS, le premier SGBD complet embarqué dans une carte à puce, destiné à la sécurisation de dossiers portables. Ce travail est récompensé par un Best Paper Award de la conférence VLDB’00 et donne lieu à l’implantation de plusieurs prototypes (sur des cartes Schlumberger obtenues grâce à un accord de coopération avec Schlumberger CP8).
J’encadre alors (depuis le DEA), Nicolas Anciaux sur le thème des bases de données embarquées sur des calculateurs ultralégers.
En 2002, je postule à l’INRIA et suis recruté en qualité de chargé de recherche 1ère classe dans le projet CARAVEL. Nous montons alors une équipe commune (PRiSM / INRIA), qui, suite à la création de Medience et au détachement de Philippe Pucheral à l’INRIA, devient une équipe INRIA en janvier 2003. L’équipe SMIS (Secured and Mobile Information Systems) dont je suis le responsable permanent depuis sa création est centrée sur les deux thématiques suivantes : (i) la gestion de données embarquées sur des calculateurs ultralégers et (ii) la préservation de la confidentialité des données par le biais de calculateurs sécurisés. SMIS deviendra un projet INRIA en octobre 2004.
Dans ce contexte, j’encadre depuis 2002, François Dang Ngoc sur le thème de la sécurisation du contrôle d’accès à des documents XML. Ces travaux donnent lieu à
2 Le projet RODIN se terminant, il céda la place au projet CARAVEL dirigé par Eric Simon.
l’implantation de plusieurs prototypes dans des contextes applicatifs très différents (e.g. travail collaboratif, contrôle parental). Ils furent récompensés par deux prix logiciels (e-gate 2004 et SIMagine 2005).
Il est tout à fait entendu que la majorité des résultats présentés dans ce document sont le fruit de collaborations multiples, comme en atteste la liste de mes publications. J'en profite pour exprimer ici ma reconnaissance à tous ceux et celles qui ont apportés leur concours à ces travaux et pour cette raison, j'utiliserai dans la suite du document la première personne du pluriel.
Travaux initiaux
Mon activité de recherche a été, et est toujours centrée sur les noyaux des Systèmes de Gestion de Bases de Données (SGBD), et notamment sur l’exécution et l’optimisation de requêtes. L’objectif de ce chapitre est de présenter rapidement mes premiers travaux antérieurs à ceux sur lesquels se concentre ce manuscrit. En effet, bien qu’ils s’attaquent à des problématiques différentes, l’approche utilisée est une approche système des bases de données, tout comme dans les études menées sur l’ubiquité et la confidentialité des données. Ce chapitre expose tout d’abord le contexte général considéré puis présente successivement les différents travaux que j’ai menés entre 1993 et 2002 sur les SGBD parallèles, les modèles d’exécution adaptatifs et enfin sur la prise en compte de fonctions coûteuses.
1. Contexte
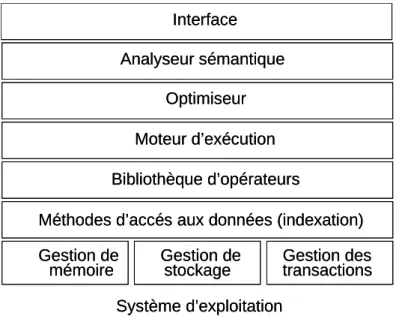
Un SGBD est un système permettant de stocker, d’organiser et de rendre facilement accessible de grands ensembles de données. Lors de l’accès à un SGBD, un utilisateur exprime sa question sous la forme d’une requête déclarative ; à savoir, la requête exprime ce que l’utilisateur désire plutôt que la façon de l’obtenir. Le SGBD doit alors produire un plan d’exécution (Query Execution Plan ou QEP) optimisé correspondant à la meilleure façon de répondre à la requête. Le terme ‘meilleure’ se traduit souvent en terme de temps de réponse, mais cela peut différer suivant le contexte (e.g. consommation de ressources, délivrance des premiers résultats, etc.). Le QEP est alors exécuté, par le moteur d’exécution, qui déclenche et contrôle l’exécution des différents opérateurs (e.g. sélection par index, jointure par hachage, etc.) qui le composent. Les opérateurs sont, eux même, définis au dessus des couches basses du SGBD, à savoir, le gestionnaire de stockage et d’indexation, le gestionnaire de mémoire et le gestionnaire transactionnel [CBB93]. La complexité des couches basses du SGBD ainsi que les opportunités d’optimisation font qu’elles se substituent généralement au système d’exploitation.
En fait, ne pouvant désactiver le système d’exploitation, les SGBDs cherchent à ne pas déclencher certains de ses mécanismes. Par exemple, pour garder le contrôle de la mémoire, les SGBDs essayent de ne pas utiliser plus de mémoire que la mémoire physique.
La figure 1 présente l’architecture en couche des SGBD. Mes contributions se situent dans les couches systèmes des SGBD, à savoir entre le système d’exploitation et l’optimisation. Elles sont décrites rapidement dans les sections suivantes.
Figure 1 : Architecture en couche d’un SGBD
2. Exécution parallèle de requêtes : l’équilibrage de charge (thèse, 1993–1996) Un des obstacles majeurs à l'obtention de bonnes performances lors de l’exécution parallèle de requêtes réside dans l'équilibrage de la charge entre les différents processeurs. En effet, le temps de réponse d'une exécution parallèle est égal au temps de réponse du processeur le plus chargé. Une mauvaise répartition de la charge de travail peut donc entraîner une chute de performance importante [Bou97].
Plusieurs remarques peuvent être faites sur les solutions proposées pour la répartition de charge: (i) à notre connaissance, aucune étude n'a cherché à résoudre le problème de la répartition de charge dans son ensemble, c'est à dire, au niveau intra opérateur (problème de mauvaises distributions des données) et inter opérateurs (problème d'allocation des processeurs aux opérateurs). (ii) les solutions au problème des mauvaises distributions de données sont généralement des solutions dynamiques (i.e. durant l'exécution), cherchant à redistribuer la charge équitablement. Le problème d'allocation des processeurs aux opérateurs est traité
Gestion de
mémoire Gestion de
stockage Gestion des transactions Méthodes d’accés aux données (indexation)
Bibliothèque d’opérateurs Moteur d’exécution
Optimiseur Analyseur sémantique
Interface
Système d’exploitation Gestion de
mémoire Gestion de
stockage Gestion des transactions Méthodes d’accés aux données (indexation)
Bibliothèque d’opérateurs Moteur d’exécution
Optimiseur Analyseur sémantique
Interface
Système d’exploitation
statiquement ou juste avant l'exécution. (iii) enfin, aucune étude n'a considéré les architectures hybrides comme les architectures hiérarchiques et NUMA qui tentent d'associer la flexibilité de l'architecture à mémoire partagée et l'extensibilité des architectures distribuées.
Ce sont ces trois points qui ont motivé notre travail dans le cadre de ma thèse. Notre approche est totalement différente des études existantes. D'une part, nous nous intéressons à des architectures hybrides et cherchons à exploiter toutes leurs possibilités. D'autre part, les mécanismes développés sont entièrement dynamiques. Enfin, nous considérons d'une manière intégrée les différentes formes de parallélisme intra requête.
Nous avons successivement abordé trois types d’architectures parallèles : (i) à mémoire partagée [BDV96, BFD96]; (ii) hiérarchique [BFV96]; et (iii) à mémoire non uniforme (NUMA) [BFV99]. Pour chacune, nous avons proposé des modèles d’exécution redistribuant dynamiquement la charge au niveau intra et inter opérateurs, en minimisant les surcoûts entraînés par cette redistribution. Pour l’architecture hiérarchique, par exemple, le modèle d’exécution proposé permet une répartition dynamique de la charge à deux niveaux (locale sur un nœud à mémoire partagée puis globale entre les nœuds). Ce modèle permet de maximiser la répartition de charge locale, réduisant ainsi le besoin de répartition de charge globale, source de surcoûts. Ces travaux ont été validés par des mesures sur le prototype DBS3 [CBB93, CDB95]
et par des simulations.
3. Modèles d'exécution adaptatifs (INRIA, 1997–1999)
Les plans d'exécution produits par les optimiseurs de requêtes traditionnels peuvent être peu performants pour plusieurs raisons : les estimations de coûts peuvent être inexactes; la mémoire disponible lors de l'exécution peut s'avérer insuffisante; et les données, si elles proviennent de sources distantes, peuvent ne pas être disponibles immédiatement, lorsqu'elles sont demandées. Classiquement, le moteur d’exécution n’a aucune marge de manœuvre et se borne à exécuter le plan d’exécution produit par l’optimiseur. C’est pourtant lors de l’exécution que l’on peut constater des problèmes comme une surconsommation de mémoire, des erreurs d’estimation, des problèmes de disponibilité des données, etc. Ces considérations motivent le développement de modèles d’exécution adaptatifs.
Dans un premier temps, nous nous sommes attachés au problème de la gestion de la mémoire lors de l’exécution de requêtes complexes dans le contexte plus simple d'un système
centralisé et proposé deux solutions [BKV98] : l'allocation statique de mémoire appliquée au lancement de l'exécution de la requête et un modèle d'exécution dynamique qui adapte l'ordonnancement de la requête en fonction de la consommation mémoire. Notre modèle d'exécution dynamique se révèle très efficace : il gère bien les débordements de mémoire et résiste aux erreurs d'estimation de coûts. Nous avons comparé nos deux solutions grâce à une combinaison d'implémentation et de simulation (pour la génération de requêtes). Les résultats sur un grand nombre de requêtes montrent des gains significatifs en performances pour notre modèle dynamique, de 50 à 85%, par rapport au modèle statique.
Nous nous sommes ensuite intéressés au problème de disponibilité des données lors de l’exécution de requêtes d’intégration de données distantes [BFV+00, BFM+00]. L’approche est à la fois prévisionnelle, en produisant un ordonnancement pas à pas de plusieurs fragments de requêtes, et réactionnelle, en exécutant ces fragments en fonction de l'arrivée des données distantes. Dans notre contexte réparti, les méta-données nécessaires à l'élaboration d'un plan d'exécution efficace peuvent être regroupées en quatre classes: les paramètres connus statiquement, avec plus ou moins d'exactitude (e.g. requête, statistiques, etc.), les paramètres qui ne sont connus qu'au début de la phase d'exécution (e.g. ressources disponibles), les paramètres qui ne seront connus avec exactitude qu'en cours d'exécution (e.g. taille des résultats intermédiaires, etc.), enfin les paramètres qui varient continuellement (e.g. débit du réseau, sources de données disponibles, taux d'arrivée des données, etc.). Nous avons développé une méthode d'optimisation et d'exécution adaptée à ce contexte : nous proposons d'exploiter les méta-données dès qu'elles deviennent disponibles. Ainsi, un plan d'exécution initial (ou du moins, un ensemble de pré-calculs qui pourront faciliter l'élaboration de ce plan) est produit avec les méta-données connues statiquement, au début de la phase d'exécution. Ce plan fixe les grandes options pour l'exécution mais laisse certains degrés de liberté, ceux qui dépendent de paramètres inconnus à ce moment. Ensuite, l'exécution se déroule en plusieurs étapes entrecoupées par des phases de planification. Une phase de planification fournit un plan d'exécution conforme aux méta-données connues à ce moment précis. Elle est suivie par une phase d'exécution qui applique le plan et qui réagit conformément à ce qui a été prévu par le planificateur. Lorsqu'un événement susceptible de remettre en cause le plan se produit, la phase d'exécution se termine et cède sa place à une nouvelle phase de planification. Cette méthode fournit un cadre générique pour l'optimisation dynamique. Son adaptation à un contexte donné demande de définir les heuristiques utilisées lors des phases de planification, les degrés de
liberté par rapport au plan initial, ainsi que les événements remettant le plan en cause. Nous avons développé plusieurs algorithmes, qui suivent cette méthode afin d'optimiser dynamiquement l'exécution des requêtes globales dans un médiateur d'accès aux données.
4. Prise en compte de fonctions coûteuses (INRIA, 1999–2002)
Internet rend possible le partage de données et de programmes entre des groupes de scientifiques. LeSelect est un système d’intégration de données, permettant d’une part la publication de ressources (données et programmes) et d’autre part, l’interrogation de ces ressources de manière transparente. Dans le cadre des applications environnementales que nous envisageons avec Le Select, les scientifiques peuvent typiquement avoir à poser des requêtes impliquant des données et des programmes (par exemple, un programme d'extraction de motifs dans une image) publiés en divers points du réseau. Même s'il est possible d'exprimer ces requêtes en SQL, les techniques classiques d'optimisation et d'exécution de requêtes sont insuffisantes pour deux raisons. Tout d'abord les optimiseurs de requêtes SQL considérant que le facteur prédominant est le coût des opérations de jointure, cherchent à minimiser ce coût en jouant sur l'ordre dans lequel sont exécutées les jointures. A contrario, dans notre contexte, le coût prédominant est celui de l'exécution des programmes et du transport des données volumineuses (telles que des images) depuis le site publiant ces données vers les lieux de traitement. D'où la nécessité d'établir des techniques d'optimisation spécifiques qui minimisent le nombre d'exécutions de programmes et la quantité de données volumineuses transférées. Dans [BFP+01], nous proposons deux techniques qui exploitent les possibilités d'optimisation inhérentes à l'architecture distribuée de systèmes comme Le Select. La première consiste à exécuter les traitements chers (appel des fonctions et transfert des données volumineuses) le plus tard possible: l'optimiseur planifie donc d'exécuter d'abord les opérations standard (sélections, jointures, etc.). La seconde consiste à utiliser un cache pour éviter des traitements redondants. Le coût total en temps d'exécution est minimisé en parallélisant l'exécution des traitements: parallélisme entre le transfert des données et l'exécution des programmes, exécution concurrente de plusieurs programmes. Le problème pour l'optimiseur est de décider de l'ordonnancement des programmes entre eux, et de décider la forme de parallélisme inter programme: parallélisme pipeline, ou parallélisme indépendant. Nous proposons des algorithmes de planification dynamique permettant de s'adapter au flot de données constaté en
cours d'exécution et montrons que l'approche dynamique peut apporter des gains considérables en termes de temps de réponse.
Dans [MBF02], nous montrons comment le modèle de relations à patterns d'accès peut être utilisé pour modéliser uniformément des sources de données contenant des fonctions ainsi que des blobs. Les patterns d'accès peuvent être utilisés de manière naturelle pour modéliser des fonctions. Nous proposons la même modélisation pour des relations contenant des objets binaires de grande taille (blobs). L'opérateur logique BindJoin est une variante de l'opérateur relationnel de jointure, utilisé pour accéder aux relations ayant des patterns d'accès. Nous analysons alors l'effet de la présence des fonctions coûteuses et des blobs sur la conception de l'opérateur de BindJoin, et sur son intégration dans un plan d'exécution de requête.
Premièrement, le travail total et le temps de réponse des requêtes nécessitant des transferts de blobs et des appels de fonctions coûteuses doivent être réduits, en utilisant des techniques de cache et d'asynchronisme. Deuxièmement, nous montrons l'importance de maximiser le taux de délivrance des résultats au début de l'exécution. L'aspect le plus spécifique de l’opérateur proposé est qu'il exploite la présence de doublons dans son entrée afin de fournir à l'utilisateur la plupart des résultats de la requête assez vite. Puisque l’opérateur de BindJoin proposé inclut toutes les optimisations, la tâche du publieur est considérablement réduite, tout en fournissant des bonnes performances.
5. Conclusion
Mon activité de recherche a donc débuté par l’étude des noyaux des SGBD, notamment l’exécution et l’optimisation de requêtes les différents contextes mentionnés précédemment.
Depuis 7 ans environs, j’ai orienté mes recherches sur les thèmes de l’ubiquité et de la confidentialité et c’est sur cette période que se concentre la suite de ce manuscrit, justifiant ainsi son titre : ‘Sécurisation du contrôle d’accès dans les bases de données’. Mon objectif, dans la suite de ce document, est de mener une analyse de différentes études que nous avons conduites, en les situant par rapport à l’état de l’art et en indiquant leur limites.
Sécurisation du contrôle d’accès dans
les bases de données
Chapitre 1 Introduction
La préservation de la confidentialité est devenue une priorité pour les citoyens ainsi que pour les administrations. Le besoin d’accumuler, de partager et d’analyser des données personnelles est multiple : pour l’amélioration de la qualité des soins grâce au dossier médical électronique (Electronic Health Record - EHR), pour rendre plus simples et efficaces les procédures administratives, pour personnaliser les services rendus par une grande quantité d’objets électroniques dans un environnement d’intelligence ambiante (e.g. [ImN02], projet
‘Aware Home‘ [AWA03]) ou même pour la lutte contre le terrorisme (croisement de bases de données commerciales et gouvernementales pour la recherche de suspects [EFF]). Bien que le traitement de données personnelles a généralement un but louable, il constitue une menace sans précédent aux droits élémentaires à la protection de la vie privée3.
Partout dans le monde, les gouvernements adoptent des lois spécifiques pour cadrer l’utilisation de données personnelles comme le ‘Federal Privacy Act’ aux USA [Pri74] ou la directive pour la protection des données en Europe [Eur85]. Il est cependant difficile de traduire ces lois en moyens technologiques convaincants garantissant leur application.
Comme l’atteste le rapport ‘Computer Crime and Security Survey’ établi par le Computer Security Institute et le FBI [CSI04], le nombre d’attaques de serveurs de bases de données est croissant malgré la mise en place de politiques de sécurité de plus en plus drastiques. Pire encore, presque la moitié de ces attaques sont conduites par des employés ayant légalement accès à tout ou partie des données. Ceci montre la vulnérabilité des techniques traditionnelles de sécurisation des serveurs bases de données [BPS96].
La sécurité des bases de données inclus trois principales propriétés : la confidentialité, l’intégrité et la disponibilité [Cup00]. Grossièrement, la propriété de confidentialité garantie que les données protégées ne seront jamais accédées par une personne ou un programme non autorisé. La propriété d’intégrité garantie la détection d’une quelconque modification des
données, qu’elle soit accidentelle ou malicieuse. Enfin, la propriété de disponibilité protège le système contre les attaques de déni de service. Ce document est centré sur la confidentialité des données. Il aborde cependant aussi l’intégrité des données car la corruption de données peut entraîner des fuites d’information (par exemple, le contrôle d’accès du SGBD peut être trompé par la modification de données sur lesquelles est basé ce contrôle).
La préservation de la confidentialité des données nécessite de mettre en application les politiques de contrôle d’accès définies au niveau du SGBD. Une politique de contrôle d’accès, i.e., un ensemble d’autorisations, peut prendre différentes formes selon le modèle de données sous jacent. Par exemple, une autorisation dans une base de données relationnelle est habituellement exprimée comme le droit d’exécuter une action donnée (e.g. sélection) sur une table relationnelle ou sur une vue (i.e., une table virtuelle calculée par une requête SQL) [Mes93]. Une autorisation sur un document XML est généralement exprimée par une combinaison de règles positives (resp. négatives) permettant de sélectionner dans le document les sous arbres autorisés (resp. interdits) grâce à des expressions XPath [BCF00, GaB01, DDP+02]. Une autre dimension des modèles de contrôle d’accès est le mode d’administration de ces autorisations, en suivant soit un modèle discrétionnaire (Discretionary Access Control - DAC) [HRU76], basé sur des rôles (Role-Based Access Control - RBAC) [SCF+96], ou sur un mode obligatoire (Mandatory Access Control - MAC) [BeL76]. Dans ce document, nous ne faisons pas d’hypothèse sur le mode d’administration de ces autorisations si ce n’est dans un but illustratif.
Indépendamment du modèle de contrôle d’accès, les limitations mises en place par le serveur de bases de données peuvent être outrepassées de plusieurs façons. Un intrus peut, par exemple, infiltrer le système d’information et examiner l’empreinte disque de la base de données. Une autre source d’attaque vient du fait que beaucoup de bases de données sont aujourd’hui externalisées chez des fournisseurs de service base de données (Database Service Providers ou DSP [CaB02, eCr02, Qck02]). Ainsi, le propriétaire des données n’a pas d’autre choix que de croire aux garanties de confidentialité des DSPs, soutenant que leur système est totalement sûr et que leurs employés sont au dessus de tout soupçon, un argumentaire
3 Remarquons que la confidentialité des données est bien sur de première importance pour la protection des données d’entreprises (stratégie commerciale, savoir faire, fichiers clients, etc.) contre l’espionnage industriel et commercial.
fréquemment contredit par des faits [HIM02]. Finalement, un administrateur de bases de données a suffisamment de pouvoirs pour modifier le mécanisme de contrôle d’accès et pour espionner le comportement du SGBD. Bien que ce constat ne soit pas nouveau ni spécifique aux systèmes électroniques de gestion de données4, il doit être considéré avec une attention particulière.
L’objectif de ce document est de présenter les différents moyens de lutte contre ces différentes formes d’attaque. La communauté bases de données s’est récemment intéressée à ce problème, considérant l’utilisation de techniques cryptographiques et de puces sécurisées pour compléter et renforcer les techniques de contrôle d’accès. Dans ce document, nous analysons et comparons différentes méthodes à base de chiffrement, hachage cryptographique, signatures ou de composants matériels sécurisés pour accroître la confiance accordée aux systèmes de gestion de bases de données afin de garantir la protection de la vie privée. Nous dégageons alors de cette étude d'importantes perspectives de recherche
Ce document est organisé comme suit. Le chapitre 2 introduit une classification des différentes attaques pouvant être conduite sur un SGBD, puis présente les instruments de bases permettant de se prémunir contre ces attaques, à savoir, les techniques cryptographiques et les composants matériels sécurisés. Le chapitre 3 présente PicoDBMS, un SGBD relationnel entièrement embarqué dans une carte à puce sécurisée. L’approche proposée dans PicoDBMS est représentative des méthodes de protection basées uniquement sur un composant matériel sécurisé. Dans le chapitre 4, nous décrivons tout d’abord les approches basées uniquement sur l’utilisation de techniques de chiffrement pour les SGBD relationnels puis présentons C-SDA, une solution combinant un serveur relationnel travaillant sur des données chiffrées et un composant embarqué dans une carte à puce. Le chapitre 5 décrit deux approches existantes utilisant des techniques cryptographiques (chiffrement, intégrité) et des composants matériels sécurisés puis présente notre approche pour l’exécution de requêtes sur des données stockées sur un serveur non sécurisé. Enfin le chapitre 6 aborde le problème de la protection de données XML, présente l’état de l’art du domaine et décrit notre approche. Le chapitre 7 conclut cette étude et présente nos perspectives de recherche.
4 Une règle spécifiant par exemple que ‘seuls les médecins peuvent accéder aux dossiers des patients’ est en fait traduite dans le cas d’archives papier par ‘les médecins et l’archiviste peuvent accéder aux dossiers des patients’.
Chapitre 2
Attaques, attaquants et instruments
Ce chapitre introduit tout d’abord quatre classes d’attaques pouvant compromettre la confidentialité des données puis présente les différents types d’attaquants pouvant conduire ces attaques. Dans une deuxième section, les instruments de base permettant de parer ces attaques sont exposés : techniques cryptographiques et composants matériel sécurisés.
L’objectif est de clarifier le problème et les éléments de solution.
1. Attaques et attaquants
Comme indiqué dans l’introduction, nous nous intéressons ici aux attaques pouvant compromettre la confidentialité des données, c'est-à-dire, aux attaques pouvant entraîner la lecture de données non autorisées. Cependant, les attaques entraînant la corruption de données doivent aussi être considérées puisqu’elles peuvent permettre de modifier les autorisations des utilisateurs. Sur des données relationnelles, ces attaques peuvent être conduites en modifiant les définitions de vues, les tables de privilèges ou les données participant à l’évaluation d’une vue autorisée. De même, dans un contexte XML, la modification de la structure du document ou simplement de la valeur de certains nœuds peut changer l’évaluation de règles positives ou négatives et donner l’accès à des données non autorisées.
Nous considérons dans la suite que l’attaquant a éventuellement accès à des données autorisées et a obtenu de manière licite ou illicite un certain accès à des données non autorisées.
C’est le cas, par exemple, d’un utilisateur qui aurait accès aux fichiers de la base de données stockés sur un serveur, voire sur un terminal portable lui appartenant5. Dans ce cas, il est impératif de protéger de manière cryptographique ces fichiers afin d’éviter que l’attaquant puisse facilement les consulter ou les modifier. Le chiffrement des fichiers est donc nécessaire et nous montrons ci-dessous quatre classes d’attaques pouvant être menées sur les fichiers de la base de données même quand ces derniers sont chiffrés.
5 Remarquons que l’utilisateur peut héberger la base de données sans toutefois avoir accès à son intégralité. C’est le cas du dossier médical personnalisé (qui gagnerait à être stocké sur un terminal portable) ou par exemple d’une base de données stockant des informations utilisées pour le contrôle d’accès à des données digitales (DRM).
• Examen des données chiffrées : L’attaquant examine les données chiffrées et déduit des informations confidentielles. En effet, suivant le mode de chiffrement, certains motifs peuvent apparaître dans les données chiffrées et peuvent laisser transparaître des informations (voir section 2).
• Corruption de données chiffrées : L’attaquant supprime ou modifie, même aléatoirement, des données dans le but de corrompre le mécanisme de contrôle d’accès.
Par exemple, la modification aléatoire d’un champ ‘age’ chiffré modifie avec une forte probabilité une règle qui autoriserait l’accès aux personnes majeures.
• Substitution de données chiffrées : L’attaquant substitue des blocs de données valides par d’autres blocs de données valides. Cette attaque, relativement simple à mener, permet de créer une information invalide à partir de données valides et donc de corrompre le contrôle d’accès.
• Rejeu de données : L’attaquant substitue des blocs de données valides par une ancienne version de ces mêmes blocs. Cette attaque permet par exemple de conserver l’accès à des données pour lesquelles les droits ont été supprimés.
Remarquons que ces attaques peuvent être menées sur les données stockées sur le disque du SGBD, sur les données en cours de traitement dans le SGBD (notamment dans les blocs mémoire du serveur) et enfin sur les données échangées sur le réseau entre le client et le serveur.
Trois classes de pirates susceptibles de mener ces attaques peuvent être distinguées en fonction de leurs privilèges initiaux :
• Le pirate externe est un intrus qui s’infiltre sur un système informatique et récupère l’empreinte disque de la base de données. [App03, Eru01] montrent que la majorité des attaques sur des systèmes informatiques ciblent les données stockées sur les disques des serveurs.
• Le pirate interne est un usager reconnu par le système d’exploitation et le SGBD. Il possède des droits sur une partie de la base de données et veut accéder à des données outrepassant ses droits. Ce pirate a potentiellement le même pouvoir qu’un pirate
externe et peut en plus exploiter ses droits restreints. [CSI04] montre qu’environ 50%
des vols d’informations proviennent d’attaques internes.
• Le pirate administrateur a suffisamment de privilèges (généralement tous) pour administrer le système informatique (administrateur système) ou la base de données (administrateur de base de données ou DBA). Ces privilèges lui permettent d’accéder aux fichiers du SGBD et d’espionner son comportement.
L’intersection entre ces différentes classes est non vide puisque, par exemple, un pirate externe peut arriver à s’octroyer les droits d’administration. L’objectif de cette classification est simplement d’associer un nom aux différentes classes d’attaquants de dangerosité croissante.
2. Instruments : Techniques cryptographiques et composants matériels sécurisés Les techniques logicielles (techniques cryptographiques) ou matérielles (e.g. puces sécurisées) décrites sommairement ci-dessous forment les outils de base pour la réalisation de systèmes de bases de données résistants aux attaques exposées dans la section précédente.
Chiffrement : Les techniques de chiffrement (ou cryptage) prennent en entrée une donnée en clair et une clé et rendent en sortie une donnée indéchiffrable à l'échelle humaine pour quiconque ne connaît pas la clé de déchiffrement. On distingue deux grandes classes d’algorithmes : (1) les algorithmes à clé secrète (e.g. DES, 3DES, AES) utilisent la même clé pour le chiffrement et le déchiffrement ; (2) les algorithmes asymétriques (e.g. RSA [RSA78]) utilisent un couple de clés, privée et publique, cette dernière pouvant être divulguée librement.
Les algorithmes asymétriques permettent de ne pas partager de secret mais sont cependant beaucoup plus lents. L’objectif du chiffrement est donc de garantir l’opacité des données (protection contre l’examen des données) en cachant l’information aux personnes non autorisées (e.g. pirate externe). Cependant, pour éviter qu’un attaquant puisse analyser les motifs répétitifs apparaissant dans les données chiffrées, il est essentiel de choisir un mode de chiffrement cachant ces motifs. La figure 2 donne un aperçu de ce problème en montrant le résultat d’un chiffrement 3-DES sur une image avec un mode ECB (chaque bloc de 8 octets est chiffré séparément) et avec un mode CBC (le résultat du chiffrement d’un bloc de 8 octets dépend des blocs précédents).
Figures empruntées au cours de à F. Schutz (http://cui.unige.ch/tcs/cours/crypto)
(a) Image originale (b) chiffrement 3-DES-ECB (c) chiffrement 3-DES-CBC Figure 2. Opacité du mode de chiffrement.
Fonctions de hachage cryptographique (FHC) : Une FHC est une fonction mathématique qui prend en entrée un texte d’une longueur quelconque et calcule une valeur de hachage, i.e., une empreinte de taille fixe (e.g. 20 octets), utilisée pour détecter toute modification accidentelle ou malicieuse du texte initial. Une FHC garantie qu’il est techniquement impossible de retrouver le texte initial à partir de la valeur de hachage ou de trouver deux textes distincts produisant la même valeur de hachage. Message Digest 5 (MD5) [Riv92] et Secure Hash Algorithm 1 (SHA-1) [NIS95] sont deux exemples classiques de FHC. Le résultat d’une FHC peut être utilisé pour détecter si une donnée a été modifiée ; il est alors appelé Code de Détection de Modification (CDM) et permet de détecter une modification d’un bit quelconque dans un texte de longueur arbitraire.
Authentification de l’origine [MOV97] : Lorsque l’on associe une clé secrète à une FHC, le résultat est appelé un Code d’Authentification de Message (CAM). Il permet de garantir que le message n’a pas été modifié lors d’une communication entre deux parties détenant la clé secrète.
L’utilisation d’algorithmes asymétriques permet d’obtenir une signature électronique, prouvant l’origine des données (le détenteur de la clé privée) et garantissant ainsi la non répudiation.
Garantie de fraîcheur : Bien que les CDM, CAM et les signatures électroniques puissent être utilisées pour prouver que les données n’ont pas été corrompues depuis leur production, ils ne donnent pas de garantie de fraîcheur. Ainsi, ces techniques, à elles seules, ne permettent pas d’éviter les attaques basées sur le rejeu. L’ajout de paramètres dépendant du temps (TVP ou time-variant parameters) permet de parer ce type d’attaques. Ces TVP peuvent être des nombres aléatoires dans des protocoles de type challenge-réponse, des numéros de séquences ou des estampilles.
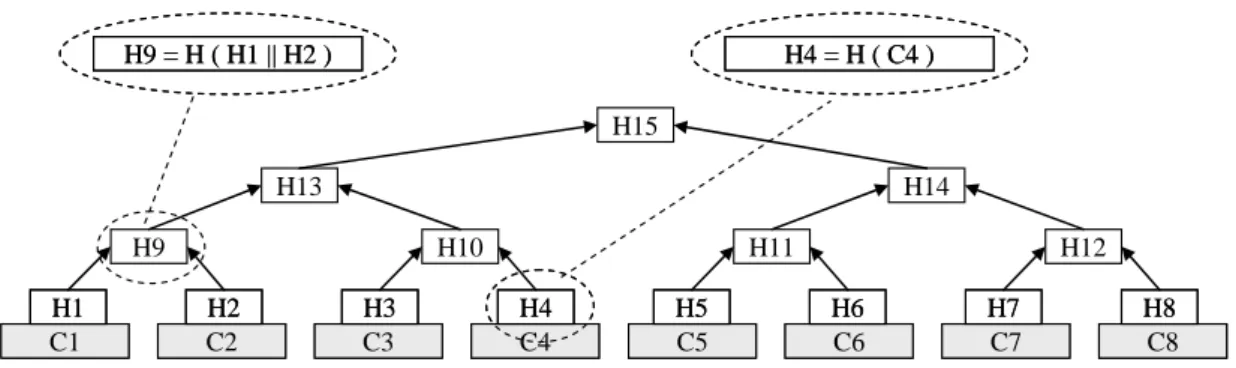
Arbres de hachage de Merkle [Mer90] : Un arbre de hachage de Merkle, ou arbre de Merkle est un arbre virtuel, calculé dynamiquement à partir des blocs de données chiffrés (feuilles de l’arbre). Il permet de garantir l’intégrité de n’importe quel bloc ou groupe de blocs en fonction d’une seule valeur de hachage correspondant à la racine de l’arbre. Comme indiqué sur la figure 3, chaque valeur de hachage intermédiaire est calculée en hachant la concaténation des valeurs de hachage des fils. Chaque valeur de hachage, au niveau des feuilles, est obtenue en hachant le bloc de données correspondant. Pour vérifier l’intégrité d’un des blocs, il est nécessaire de calculer son hachage et de la combiner avec quelques valeurs de hachage afin de recalculer la valeur racine à comparer avec la valeur espérée. Dans l’exemple de la figure 3, pour prouver l’intégrité du bloc C4, il est nécessaire de récupérer les valeurs de hachage H3, H9 et H14 afin de calculer H15’=H (H14||H (H9||H (H3||H(C4))) et de le comparer avec H15.
C1 H1 C1 H1
C2 H2 C2 H2
C3 H3 C3 H3
C5 H5 C5 H5
C6 H6 C6 H6
C8 H8 C8 H8 C7
H7 C7 H7
H9 H10 H11 H12
H13 H14
H15 H9 = H ( H1 || H2 )
H9 = H ( H1 || H2 )
C4 H4 C4 H4
H4 = H ( C4 ) H4 = H ( C4 )
Figure 3. Arbre de hachage de Merkle.
Composants matériels sécurisés : Les coprocesseurs sécurisés [Swe99, DLP+01] et les cartes à puces [Tua99] sont aujourd’hui les composants matériels sécurisés les plus largement utilisés.
Ils garantissent que le code et les données embarqués ne peuvent être corrompus ni accédés de manière illicite grâce à des mécanismes de sécurité matériels et logiciels. Dans les cartes à puces, par exemple, des couches de métal couvrent la puce et permettent de détecter toute tentative d’intrusion, les radiations produites par le processeur pendant le traitement sont limitées, la consommation d’énergie ainsi que la température de la puce sont maintenue constantes afin de contrer toute analyse, les comportements anormaux sont évités grâce à des détecteur de basse fréquence et de voltage anormal désactivant la puce. Ainsi les données et/ou programmes chargés sur ces composants sont stockés/exécutés correctement ou sont détruits en cas d’intrusion.
Chapitre 3
PicoDBMS, une approche basée sur un composant matériel sécurisé
Une solution drastique pour garantir la sécurité du code du SGBD et des données consiste à embarquer l’ensemble dans un environnement d’exécution sécurisé (Secured Operating Environment ou SOE [HeW01]), héritant ainsi de sa sécurité intrinsèque. La carte à puce est un très bon exemple de SOE ; elle présente une sécurité inégalable [AnK96] pour les données et le code embarqué, permettant de résister aux attaques identifiées dans le chapitre 2. Ce constat nous a conduit à proposer PicoDBMS, le premier SGBD relationnel complet embarqué dans une carte à puce [BBP00, PBV+01]. Ce chapitre résume tous d’abord l’état de l’art, détaille les contraintes des cartes à puce et leur influence sur la conception d’un SGBD puis présente succinctement notre contribution. Les limitations de PicoDBMS et de l’approche ‘tout embarqué’ en général sont alors discutées. Finalement, les résultats les plus significatifs de cette étude sont présentés.
1. Etat de l’art
Peu de travaux ont porté jusqu’à présent sur la gestion de données embarquées au sein de la communauté bases de données. Les premiers travaux émanent des éditeurs de SGBD qui dérivent aujourd’hui des versions allégées de leurs systèmes pour des assistants personnels (e.g.
Sybase Adaptive Server Anywhere [Gig01], Oracle 9i Lite [Ora02], SQLServer for Windows CE [SeG01] or DB2 Everyplace [KLL+01]). Leurs préoccupations concernent la réduction de l’empreinte disque du SGBD [Gra98] ainsi que sa portabilité, mais le problème spécifique et plus complexe d’embarquer un SGBD dans une puce n’est pas adressé.
Les membres de l’équipe RD2P du laboratoire LIFL, associés à Gemplus ont pour la première fois suggéré l’idée d’une carte à puce à interface SQL, aboutissant à la carte CQL (Card Query Language) [Gri92, Gem92, PaV94a, PaV94b]. Ces travaux ont conduit à la
définition du standard ISO SCQL [ISO99] spécifiant un langage bases de données pour carte à puce et à un produit industriel (ISOL’s SQLJava Machine [Car99]). Ces propositions considéraient une génération de cartes disposant de 8 KB de mémoire persistante. Bien que leur conception soit limitée à des requêtes mono-table, ces travaux illustrent l'intérêt de concevoir un SGBD dédié pour carte à puce. Plus récemment, MODS, l'initiative de Mastercard [Mas02], offre une API commune permettant aux commerçants, banques et autres organisations d'accéder et de stocker des données sur les cartes à puces des utilisateurs avec une sécurité accrue pour le porteur de carte. Cependant, MODS est basé sur des fichiers plats (et donc non compacts), des droits d'accès grossiers (au niveau du fichier) et n'offre aucune possibilité d'exécution de requête. Néanmoins, cette initiative montre l'intérêt du développement de techniques bases de données pour ces environnements.
Une étude récente propose des techniques de stockage spécifiques pour gérer des données dans une puce contenant de la mémoire FLASH [BSS+03]. Là encore, la conception se limite à des requêtes mono-table et est fortement orientée par l'architecture du type de puce ciblé. Ainsi, ce travail propose de stocker les données dans de la mémoire FLASH de type NOR, généralement substituée à la ROM et dédiée au stockage des programmes. Vu que les modifications dans une FLASH NOR sont très coûteuses (une simple modification impose l'effacement très coûteux d'un large bloc de données), les techniques envisagées sont orientées vers la minimisation du coût de modification. Bien que cette étude montre l'impact des propriétés matérielles sur le noyau du SGBD, elle ne satisfait pas les contraintes des cartes et ne traite pas de l'exécution des requêtes complexes, nécessaires au calcul des données autorisées.
2. Approche
Les cartes à puce actuelles disposent d'un processeur 32 bit cadencé à 50 MHz, de modules mémoire dotés de 96 KB de ROM, 4 KB de RAM et 64 KB d'EEPROM, et de modules de sécurité (générateur de nombres aléatoires, co-processeur cryptographique, etc.). La ROM stocke le système d'exploitation, des données statiques et des routines standard. La RAM sert de mémoire de travail (pile et tas). L'EEPROM stocke les informations persistantes, les données et les applications téléchargées (dans le cas de cartes multi-applications).
Les ressources internes de la puce présentent des asymétries originales. Le processeur, calibré pour effectuer des calculs cryptographiques et assurer la sécurité de la puce, est
surdimensionné par rapport au volume de données embarquées. De plus, la mémoire persistante (EEPROM) partage les caractéristiques d'une mémoire RAM en terme de granularité (accès direct à chaque mot en mémoire) et de performance de lecture (60 à 100 ns par mot), mais souffre d'un temps d'écriture extrêmement lent (environ 10 ms par mot). Enfin, seules quelques centaines d'octets de RAM sont disponibles pour les applications embarquées, la majeure partie de la RAM étant réservée au système d'exploitation et à la machine virtuelle (cartes Java). Ces caractéristiques entraînent une reconsidération en profondeur de l’ensemble des techniques de gestion de bases de données et nous amènent à suivre les six règles de conception suivantes :
• Règle de compacité : minimiser l'empreinte des données, des index, et du code de PicoDBMS pour s'adapter à la quantité réduite de mémoire persistante ;
• Règle de la RAM : minimiser la consommation RAM des opérateurs vu sa taille extrêmement limitée ;
• Règle d'écriture : minimiser les écritures en mémoire persistante vu leur coût très élevé (≈10 ms/mot) ;
• Règle de lecture : tirer parti des lectures rapides en mémoire persistante (≈100 ns/mot) ;
• Règle d'accès : tirer parti de la fine granularité et de l'accès direct à la mémoire persistante pour les opérations de lecture et d'écriture ;
• Règle de sécurité : ne jamais externaliser de donnée sensible hors de la puce et minimiser la complexité algorithmique du code pour éviter les trous de sécurité ;
• Règle du CPU : tirer parti de la puissance surdimensionnée du CPU, comparée au volume de données embarquées.
3. Contribution
Les modules embarqués dans la puce pour garantir la confidentialité sont : un module de stockage organisant les données et les index associés dans la mémoire persistante de la puce, un évaluateur de requêtes capable de construire et d’exécuter des plans d’exécution complexes (composés d'opérateurs de sélection, projection, jointures et calculs d’agrégats), un module de droits d’accès offrant la possibilité de donner/retirer des droits sur les vues définies (évitant ainsi d'externaliser des données non autorisées), et finalement un moteur transactionnel assurant l'atomicité de séquences de modifications. Dans la suite, nous présentons succinctement le modèle de stockage et les techniques d’évaluations de requêtes associées. Pour plus de détails, le lecteur peut se référer à l’article joint en annexe A.
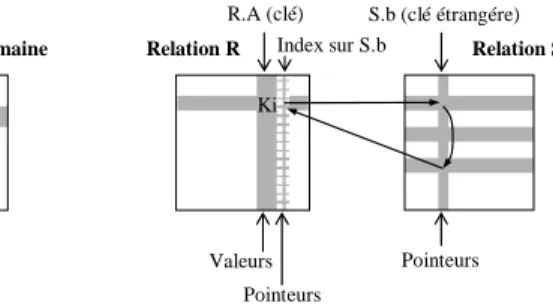
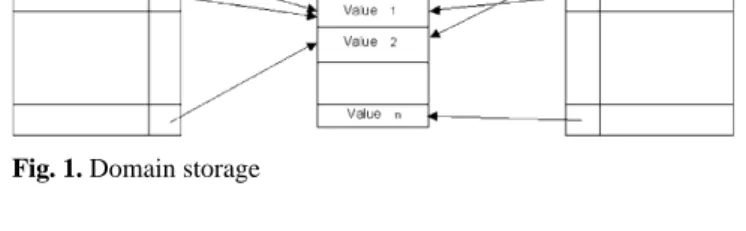
Le modèle de stockage d’un PicoDBMS doit garantir au mieux la compacité des données et des index. Dès lors que la localité des données n’est pas un problème (règle d'accès), un modèle de stockage basé sur l’utilisation intensive de pointeurs inspiré des SGBD grande mémoire [MiS83, AHK85, PTV90] favorise la compacité. Pour éliminer les doublons, nous regroupons les valeurs dans des domaines. Les enregistrements référencent leurs valeurs d’attributs avec des pointeurs. Ce stockage complexifie la mise à jour mais diminue son coût simplement parce qu’elle génère moins d’écritures (règle d'écriture).
Les index doivent eux aussi être compacts. En supposant que l’attribut indexé prenne valeur sur un domaine, nous proposons de construire une structure accélératrice en forme d’anneau partant de la valeur de domaine vers les enregistrements, comme le montre la figure 4.a. Le coût de ce stockage indexé est réduit à son minimum, c’est à dire un pointeur par valeur de domaine, quelque soit la cardinalité de la relation indexée, au prix d’un surcoût de projection des enregistrements, dû au parcours, en moyenne, de la moitié de la chaîne de pointeurs pour retrouver la valeur d’attribut.
Valeur i Domaine Relation R
Valeurs
S.b (clé étrangére) Relation R
R.A (clé)
Relation S
Pointeurs Index sur S.b
Valeurs Pointeurs
R.a Index sur R.a
Pointeurs Pointeurs
Ki
(a) RS sur un attribut régulier. (b) RS sur un attribut clé étrangère.
Figure 4. Stockage en anneau (RS).
Les index de jointure [Val87] peuvent être construits d’une manière similaire. La figure 4.b montre un index de jointure en anneau entre les relations R et S. R.a est une clé stockée ‘à plat’
et un anneau est construit partant de R.a vers tous les tuples de S pour lesquels S.b = R.a.
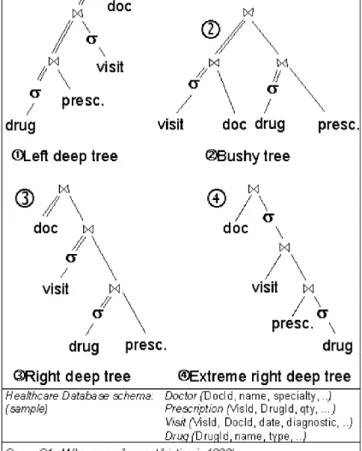
L’exécution traditionnelle de requêtes exploite la mémoire de travail pour stocker des structures temporaires (e.g. tables de hachage) et des résultats intermédiaires, et en cas de débordement mémoire matérialise des résultats sur disque. Ces algorithmes ne peuvent être utilisés dans un PicoDBMS (règles de la RAM et d'écriture). Nous proposons d’exécuter les requêtes de type SPJ (sélection, projection, jointure) en ‘pipeline extrême’, i.e., tous les opérateurs travaillent en pipeline, tuple par tuple, y compris les sélections (cf. figure 5). Les
opérandes de gauche étant toujours les relations de base, elles sont déjà matérialisées en mémoire persistante, ce qui permet d'exécuter la requête sans consommer de RAM. L’exécution pipeline peut être réalisée en utilisant le modèle itérateur [Gra93], où chaque opérateur supporte trois appels de procédures : open prépare l’opérateur à produire un résultat, next produit un résultat, et close libère les structures et termine l’opérateur. L’exécution commence à la racine de l’arbre et se propage jusqu’aux feuilles, le flux de données étant constitué des tuples passés par un opérateur fils à son père en réponse à un appel next. Bien que les plans d’exécution ainsi générés soit clairement sous optimaux (e.g. une requête contenant plusieurs sélections ne pourra profiter pleinement de leur sélectivité), les performances restent correctes du fait du surdimensionnement du CPU (règle du CPU) et du modèle de stockage en anneau.
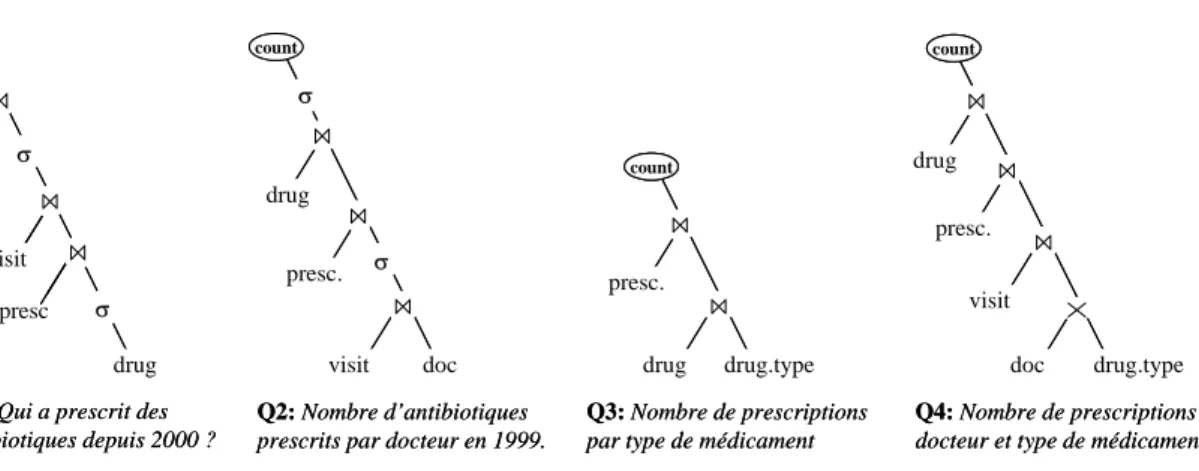
Le problème se complexifie lorsqu’il s’agit d’exécuter des requêtes contenant des opérateurs de calculs d’agrégats. En effet, l’exécution pipeline parait incompatible avec ces opérateurs, s’exécutant traditionnellement sur des résultats intermédiaires matérialisés. Nous proposons une solution au problème exploitant deux propriétés : (1) les calculs d’agrégat peuvent être réalisés en pipeline sur un flot de tuples groupés par valeur distincte, et (2) les opérateurs fonctionnant en pipeline préservent l’ordre des tuples puisqu’ils consomment (et produisent) les tuples dans l’ordre d’arrivée. Ainsi, la consommation dans un ordre adéquat des tuples aux feuilles de l’arbre permet d’effectuer les calculs d’agrégat en pipeline. Ces techniques permettent d’exécuter des requêtes contenant des agrégats sans consommation de RAM au prix d’itérations multiples sur les données. Considérons maintenant la requête Q2 de la figure 5.
L'évaluation de cette requête en pipeline nécessite de former l'arbre de manière à parcourir Doctor en premier. Vu que la relation Doctor contient des docteurs distincts, les tuples arrivant à l'opérateur count sont naturellement groupés par docteur. Le cas de Q3 est complexe. Les données devant être groupées par type de Drug, une jointure additionnelle est nécessaire entre la relation Drug et le domaine Drug.type. Les valeurs du domaine étant uniques, cette jointure produit les tuples dans l'ordre adéquat. Le cas de Q4 est plus complexe encore. Le résultat doit être groupé sur deux attributs (Doctor.id et Drug.type), nécessitant de commencer le parcours à partir des deux relations. La solution est d'insérer un produit cartésien en bas de l'arbre pour produire les tuples ordonnés par Doctor.id et Drug.type. Dans ce cas, le temps de réponse de la requête est environ n fois plus grand (n étant le nombre de types de Drug distincts) que celui de la même requête sans clause de groupement.
visit doc drug
presc. σ σ
count
drug drug.type presc.
count
visit drug
presc.
count
doc drug.type Q2: Nombre d’antibiotiques
prescrits par docteur en 1999.
Q3: Nombre de prescriptions par type de médicament
Q4: Nombre de prescriptions par docteur et type de médicament drug
visit doc
presc σ σ
Q1: Qui a prescrit des antibiotiques depuis 2000 ?
visit doc drug
presc. σ σ
count
drug drug.type presc.
count count
visit drug
presc.
count count
doc drug.type Q2: Nombre d’antibiotiques
prescrits par docteur en 1999.
Q3: Nombre de prescriptions par type de médicament
Q4: Nombre de prescriptions par docteur et type de médicament drug
visit visit doc doc
presc presc σ
σ
Q1: Qui a prescrit des antibiotiques depuis 2000 ?
Figure 5. Plans d’exécution ‘pipeline extrême droit’
4. Conclusion
PicoDBMS apporte donc une solution effective pour la protection de données confidentielles contre les attaques mentionnées dans le chapitre 2. Ce haut degré de sécurité est obtenu grâce aux 3 propriétés suivantes : (1) la protection matérielle de la puce ; (2) les données et le code sont embarqués sur la puce ; et (3) PicoDBMS est suffisamment simple pour ne pas nécessiter d’administration.
Les limites de PicoDBMS, et plus généralement de l’approche ‘tout embarqué’ résident précisément en ces trois points. En effet, la protection matérielle est obtenue au prix de fortes contraintes sur les ressources. Par exemple, les prototypes de cartes à puces les plus avancés sont limités à 1 mégaoctet d’espace de stockage. De plus, l'accès aux données embarquées ne peut évidemment se faire que lorsque la carte est physiquement connectée au réseau, limitant ainsi l’applicabilité de l’approche aux applications de type dossiers portables sécurisés. Il est raisonnable de penser qu’à long terme ces contraintes pourraient disparaître, permettant d’embarquer une base de donnée de taille importante ainsi qu’un SGBD plus puissant qui pourrait même être connecté au réseau, comme un véritable serveur de bases de données.
Malheureusement, cette évolution conduirait inévitablement à un SGBD plus complexe nécessitant un administrateur, et par là même, réintroduirait le problème des attaques de l’administrateur.
5. Résultats
Le design initial de PicoDBMS a été publié en 2000 [BBP00] et a été récompensé par le Best Paper Award de VLDB [PBV+01]. Un prototype complet de PicoDBMS a été initialement développé en JavaCard [Sun99] et démontré à la conférence VLDB’2001 [ABB+01]. Ce prototype validait le fonctionnement des techniques proposées mais ses performances étaient très faibles. Il a été réécrit en langage C (et optimisé dans un souci de performance), et récemment adapté à ‘Zeplatform’, le système d'exploitation servant de base à la prochaine génération de cartes à puce d'Axalto. Trois ans ont été nécessaires à l'obtention de ces cartes et à l'adaptation (avec l'aide d'Axalto) du noyau du système d'exploitation pour satisfaire les exigences de performances des applications embarquées orientées données. Un banc d’essai dédié aux bases de données de type PicoDBMS a été défini et utilisé pour juger des performances relatives des différentes structures de stockage et d'indexation des données [ABP05a]. Un article concluant cette étude a été récemment soumis à la revue TODS [ABP05b]
dans lequel nous reconsidérons le problème initial à la lumière des évolutions matérielles des cartes et des nouveaux besoins applicatifs. Une analyse de performance détaillée de notre prototype y est présentée ainsi que d’importantes perspectives de recherche dans le domaine de la gestion de données dans les puces sécurisées.
Les travaux relatifs à PicoDBMS ont constitué une partie du travail de thèse de Christophe Bobineau [Bob02] et de Nicolas Anciaux [Anc04].
Chapitre 4
C-SDA, une approche hybride utilisant un SGBD relationnel
Ce chapitre présente Chip-Secured Data Access (C-SDA), une solution basée sur le chiffrement de la base de données côté serveur et sur un traitement sécurisé dans une puce, côté client. Dans une première section, nous étudions les techniques existantes, à base de chiffrement seul, et montrons qu’elles ne permettent pas de se protéger contre les attaques d’un administrateur malveillant, ou qu’elles ne permettent pas le partage de données entre plusieurs clients. Nous présentons alors C-SDA qui suit une approche hybride (chiffrement + puce sécurisée). Son principe général est présenté dans la section 2 et les éléments les plus significatifs de la solution sont détaillés dans la section 3. Les limitations de C-SDA sont discutées dans la section 4. Finalement, nous présentons les résultats les plus significatifs de cette étude.
1. Etat de l’art
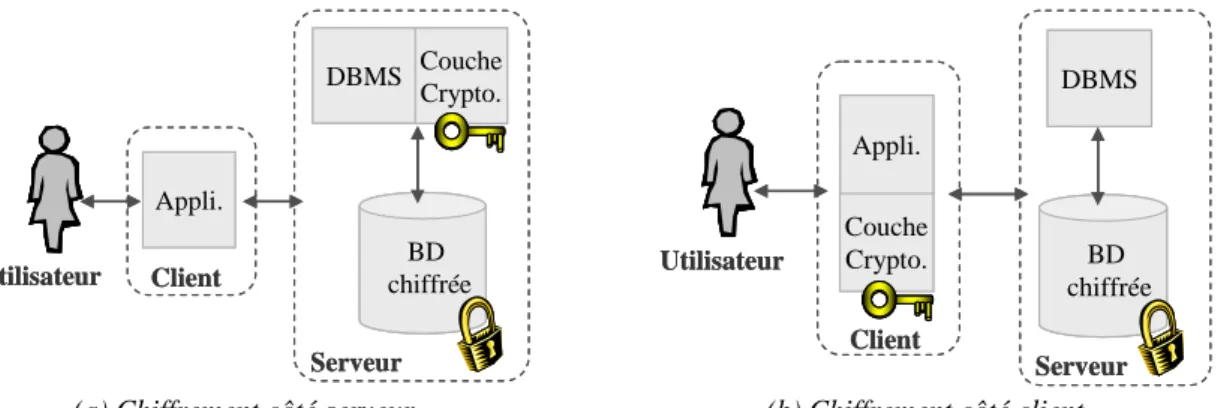
Les éditeurs de SGBD proposent des outils cryptographiques pour chiffrer les données de la base. DB2 UDB inclut des fonctions de chiffrement permettant de chiffrer les tuples au niveau de chaque attribut [IBM03]. Oracle fournit un package PL/SQL ‘Oracle Obfuscation Toolkit’ permettant de chiffrer des chaînes de caractères et des données binaires [Ora01, Ora02].
Finalement, Microsoft SQL Server 2000 permet de chiffrer les communications réseau ainsi que les métadonnées (e.g. la définition des vues). L’architecture fonctionnelle présentée figure 6.a est représentative de ces méthodes. Le chiffrement permet de se protéger contre des attaques externes. Cependant, les données sont déchiffrées sur le serveur lors du traitement des requêtes, les clés étant soit transmises par le client, soit conservées sur le serveur. Ainsi, ces techniques ne permettent pas de résister aux attaques d’un DBA car celui-ci possède le moyen d’intercepter les clés, de substituer le package de chiffrement par un autre [HeW01], ou encore, peut espionner la mémoire du serveur lors de l’exécution. Dans [IMM+04], un modèle de stockage optimisé pour supporter un chiffrement partiel des données est présenté. Ce modèle, inspiré du modèle PAX [ADH+01] décompose les tuples verticalement, chaque colonne étant chiffrée séparément afin de minimiser la quantité de données à déchiffrer. Cette solution souffre cependant des mêmes défauts que les approches commerciales.
BD chiffrée Utilisateur Client
Serveur Appli.
DBMS Couche Crypto.
BD chiffrée
BD chiffrée Utilisateur Client
Serveur Appli.
DBMS Couche Crypto.
Couche Crypto.
Utilisateur
Client Appli.
BD chiffrée
Serveur DBMS
Couche Crypto.
Utilisateur
Client Appli.
BD chiffrée
BD chiffrée
Serveur DBMS
(a) Chiffrement côté serveur. (b) Chiffrement côté client.
Figure 6. Architectures de SGBD exploitant le chiffrement
Une solution complémentaire au chiffrement a été récemment proposée pour protéger la base de données des attaques de l’administrateur. Protegrity [Mat04] introduit une distinction claire entre le rôle du DBA, qui administre les ressources de la base de données et le rôle du SA (Administrateur de Sécurité), qui administre les privilèges des utilisateurs, les clés, et d’autres paramètres ayant trait à la sécurité. Cette distinction est aussi faite au niveau système en séparant physiquement le serveur de bases de données et le serveur de sécurité. La sécurité de la solution repose donc sur une séparation stricte des serveurs et des rôles (DBA / SA), une attaque nécessitant alors une association entre le DBA et le SA. Bien que Protegrity soit compatible avec la plupart des SGBD, il n’apporte qu’une protection relative puisque les données sont toujours déchiffrées sur le serveur lors du traitement des requêtes.
Pour contourner cette faiblesse, plusieurs études académiques proposent d’effectuer le déchiffrement du côté client [HIM02, HIL+02, DDJ+03], correspondant alors à l’architecture fonctionnelle de la figure 6.b. Ainsi, la couche cryptographique ainsi qu’une partie du traitement des requêtes sont déportés sur le client. La requête initiale est divisée en deux sous requêtes. La première est évaluée sur le serveur, directement sur les données chiffrées, grâce à des index flous ajoutés aux données chiffrées, et retourne un sur ensemble du résultat. La seconde sous requête est traitée sur le client, après déchiffrement des résultats de la première sous requête.
Remarquons que l’utilisation d’index plus précis permet d’optimiser les performances mais augmente le risque d’inférence d’information non autorisée à partir des données chiffrées.
[DDJ+03] étudie l’équilibre entre précision et confidentialité. Remarquons que ces approches ont été proposées pour protéger des bases de données externalisées chez un DSP (Database Service Provider ou fournisseur de services bases de données) mais n’ayant pas vocation à être partagées entre plusieurs utilisateurs ayant des droits différents.
2. Approche
Ainsi, les techniques déchiffrant les données sur le serveur ne permettent pas de se protéger contre un administrateur malveillant, ou contre un intrus ayant acquis les droits de l’administrateur. Celles, déchiffrant les données sur le client, ne permettent pas le partage (car la connaissance des index permettrait d’inférer des informations non autorisées) et nécessitent la présence d’index à partir desquels il est possible d’inférer certaines informations.
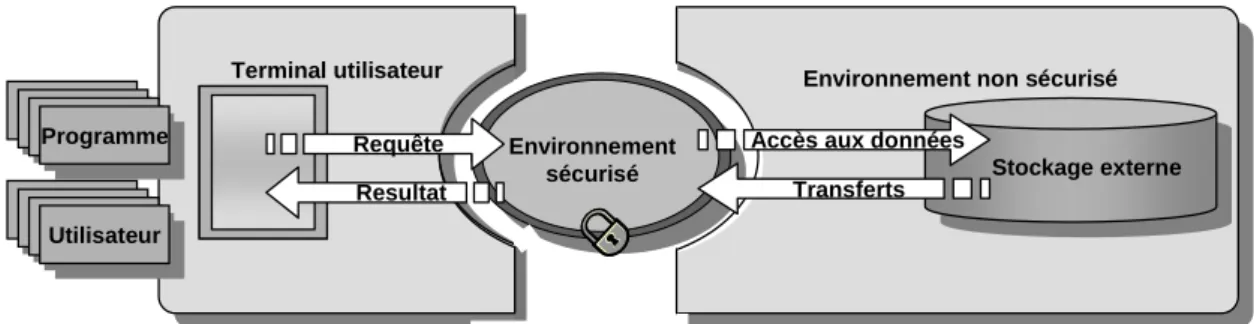
Nous avons proposé, dans [BoP02], de déporter du SGBD l’ensemble des fonctions de sécurité (gestion des droits, des vues des clés, déchiffrement, etc.) dans un environnement sécurisé (SOE), qui s’interface entre le client et le serveur. En effet, le déchiffrement des données ne peut s’effectuer sur le serveur (risques d’attaques du DBA), ni sur le client (risques d’attaques du client ou pas de partage). Ce module de sécurité appelé C-SDA est embarqué dans une carte à puce et agit comme un médiateur incorruptible entre le client et le serveur.
Le schéma de la base de données ainsi que les données sont chiffrées par C-SDA au niveau de chaque attribut en respectant la contrainte suivante : ∀a, ∀b, a=b ⇔ Chiffre(a)=Chiffre(b).
Lorsque le client soumet une requête, celle-ci est interceptée par C-SDA. Les droits sont alors vérifiés. La requête, si elle met en jeu des vues, est traduite en une requête portant sur les relations de base. C-SDA transmet au serveur une partie de la requête, qui effectue le maximum de traitement sur les données chiffrées. Le résultat est transmis à la carte à puce, déchiffré puis traité par C-SDA qui complète éventuellement l’exécution de la requête, délivrant uniquement les données autorisées au client. La difficulté est d’obtenir au final, un processus suffisamment performant malgré les fortes contraintes des cartes à puce. La section suivante détaille certains éléments de la solution, le lecteur pouvant se référer à l’article initial en annexe B.
3. Contribution
La requête Q doit être décomposée en une partie Qs évaluable par le serveur sur les données chiffrées et son complément Qc à évaluer par la puce sur le résultat partiel, après déchiffrement. Il est fondamental que Qc puisse être exécutée par la puce et non par le terminal pour éviter d’externaliser des données non autorisées. Par exemple, un utilisateur peut avoir le droit de consulter le résultat d’un calcul d’agrégat sans pour autant posséder le droit de consulter les données élémentaires à partir desquelles cet agrégat est calculé.
Pour que ce principe soit applicable sur une carte à puce, il faut que l’évaluation de Qc par C-SDA puisse se faire en respectant les contraintes inhérentes à la carte (cf. chapitre 3, section 2). Ces contraintes imposent d’évaluer Qc sans jamais matérialiser de rés